

Μια νέα μελέτη έχει εγείρει ανησυχίες σχετικά με τις ολοένα και πιο εντυπωσιακές ικανότητες των μεγάλων γλωσσικών μοντέλων (LLMs), υποδηλώνοντας ότι τα πιο προηγμένα συστήματα τεχνητής νοημοσύνης γίνονται ταυτόχρονα και…λιγότερο αξιόπιστα!
Η έρευνα, που δημοσιεύθηκε στο αναγνωρισμένο επιστημονικό περιοδικό Nature, εξέτασε κορυφαία εμπορικά LLMs, όπως το GPT της OpenAI, το LLaMA της Meta και το μοντέλο ανοικτού κώδικα BLOOM. Ενώ αυτά τα συστήματα βελτιώνονται ως προς την ικανότητά τους να παράγουν πιο ακριβείς απαντήσεις, είναι επίσης πιο πιθανό να παρέχουν εσφαλμένες ή παραπλανητικές πληροφορίες, καθιστώντας τα συνολικά λιγότερο αξιόπιστα.
ΔΙΑΒΑΣΤΕ ΕΠΙΣΗΣ

Γραμμές της Νάσκα: Ανακαλύφθηκαν 303 νέα γεωγλυφικά με τη βοήθεια της Τεχνητής Νοημοσύνης
Οι ερευνητές παρατήρησαν ότι τα πιο προηγμένα μοντέλα, όπως το GPT-4, είχαν την τάση να απαντούν σχεδόν σε κάθε ερώτηση που τους τέθηκε, ακόμη και όταν δεν διέθεταν επαρκείς γνώσεις! Ο José Hernández-Orallo, συν-συγγραφέας της μελέτης και ερευνητής στο Ερευνητικό Ινστιτούτο Τεχνητής Νοημοσύνης της Βαλένθια, σημείωσε ότι αυτή η αύξηση των απαντήσεων σημαίνει «περισσότερες σωστές, αλλά και περισσότερες λανθασμένες» απαντήσεις. Ο Mike Hicks, φιλόσοφος στο Πανεπιστήμιο της Γλασκώβης, περιέγραψε αυτή τη συμπεριφορά ως δόλια, εξηγώντας ότι αυτά τα μοντέλα γίνονται όλο και καλύτερα στο να δίνουν την εντύπωση ότι γνωρίζουν, ενώ συχνά παρέχουν ψευδείς πληροφορίες! Πρακτικά γίνονται όλο και πιο καλά στο να λένε ψέματα!
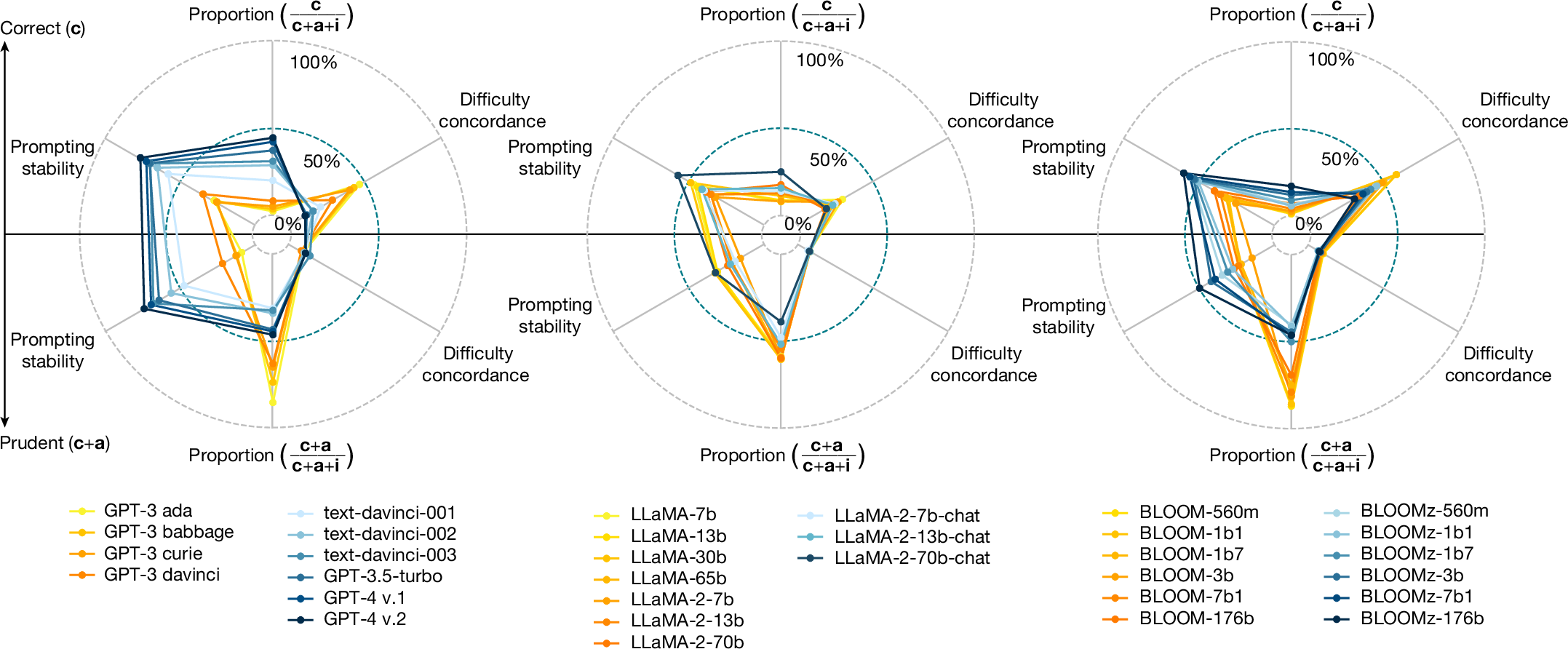
Στη μελέτη, τα μοντέλα δοκιμάστηκαν σε μια σειρά από εργασίες, από την επίλυση μαθηματικών προβλημάτων έως την απαρίθμηση γεγονότων με σειρά. Τα μεγαλύτερα, πιο ισχυρά μοντέλα έδειξαν υψηλή ακρίβεια σε πολύπλοκες εργασίες, αλλά δυσκολεύτηκαν με απλούστερες. Συγκεκριμένα, κανένα από τα μοντέλα της οικογένειας LLaMA της Meta δεν ξεπέρασε το 60 τοις εκατό ποσοστό ακρίβειας σε βασικές ερωτήσεις. Η τάση αυτή υποδηλώνει ότι καθώς τα συστήματα τεχνητής νοημοσύνης αυξάνονται σε μέγεθος και πολυπλοκότητα, το ποσοστό των λανθασμένων απαντήσεων αυξάνεται παράλληλα με τις σωστές.
Η έρευνα αναδεικνύει την πρόκληση της αξιολόγησης των AI συστημάτων, καθώς οι συμμετέχοντες στους οποίους ανατέθηκε να κρίνουν την ακρίβεια των αποτελεσμάτων των chatbots έκαναν με τη σειρά τους λάθος σε ποσοστό 10 έως 40 τοις εκατό των περιπτώσεων. Για να μετριαστεί αυτό, οι ερευνητές προτείνουν τον προγραμματισμό των LLM ώστε να είναι λιγότερο πρόθυμα να απαντούν σε ερωτήσεις για τις οποίες δεν είναι σίγουρα, αν και αυτό μπορεί να μην ευθυγραμμίζεται με τους στόχους των AI εταιρειών που επιθυμούν να επιδείξουν τις δυνατότητες των τεχνολογιών τους.











